Information mutuelle
Information mutuelle
Un article de Wikipédia, l'encyclopédie libre.
Dans la théorie des probabilités et la théorie de l'information, l'information mutuelle de deux variables aléatoires est une quantité mesurant la dépendance statistique de ces variables. Elle se mesure souvent en bit.
L'information mutuelle d'un couple (X,Y) de variables représente leur degré de dépendance au sens probabiliste. Ce concept de dépendance logique ne doit pas être confondu avec celui de causalité physique, bien qu'en pratique l'un implique souvent l'autre.
Informellement, on dit que deux variables sont indépendantes si la réalisation de l'une n'apporte aucune information sur la réalisation de l'autre. La corrélation est un cas particulier de dépendance dans lequel la relation entre les deux variables est strictement monotone.
L'information mutuelle est nulle ssi les variables sont indépendantes, et croit lorsque la dépendance augmente.
Sommaire[masquer] |
Définition [modifier]
Soit (X,Y) un couple de variables aléatoires de densité de probabilité jointe données par P(x,y). Notons les distributions marginales P(x) et P(y). Alors l'information mutuelle est dans le cas discret:

et, dans le cas continu:

Propriétés [modifier]
- I(X, Y) = 0 ssi X et Y sont des variables aléatoires indépendantes.
- L'information mutuelle est positive ou nulle.
- L'information mutuelle est symétrique.
- 'Data processing theorem': si g1 et g2 sont deux fonctions mesurables alors
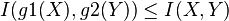 . Ceci signifie qu'aucune tranformation sur les données brutes ne peut faire apparaitre de l'information.
. Ceci signifie qu'aucune tranformation sur les données brutes ne peut faire apparaitre de l'information.
Plusieurs généralisations de cette quantité à un nombre plus grand de variables ont été proposées, mais aucun consensus n'a encore émergé.
Liens avec la théorie de l'information [modifier]
Entropie [modifier]
L'information mutuelle mesure la quantité d'information apportée en moyenne par une réalisation de X sur les probabilités de réalisation de Y. En considérant qu'une distribution de probabilité représente notre connaissance sur un phénomène aléatoire, on mesure l'absence d'information par l'entropie de cette distribution. En ces termes, l'information mutuelle s'exprime par:
- I(X,Y) = H(X) − H(X | Y) = H(Y) − H(Y | X) = H(X) + H(Y) − H(X,Y).
où H(X) et H(Y) sont des entropies, H(X|Y) et H(Y|X) sont des entropies conditionnelles, et H(Y,X) est l'entropie conjointe entre X et Y.
Ainsi on voit que I(X,Y) = 0 ssi le nombre de bits nécessaires pour coder une réalisation du couple est égal à la somme du nombre de bits pour coder une réalisation de X et du nombre de bits pour coder et une réalisation de Y.
Divergence de Kullback-Leibler [modifier]
L'information mutuelle peut aussi être exprimée par la divergence de Kullback-Leibler. On a

Ainsi I(X,Y) mesure une sorte de "distance" entre les distributions P(X,Y) et P(X) * P(Y). Comme, par définition, deux variables sont indépendantes ssi ces deux distributions sont égales, et comme KL(p,q) = 0 ssi p = q, on retrouve l'équivalence entre I(X,Y) = 0 et indépendance.
Intuitivement P(X,Y) porte plus d'information lorsque les variables sont dépendantes que lorsqu'elles ne le sont pas. Si les deux variables sont discrètes à N cas, il faut, au pire, N2 − 1 coefficients pour spécifier P(X,Y), contre seulement 2N − 1 si P(X,Y) = P(X)P(Y).
La divergence KL donne le nombre de bits d'information apportés par la connaissance de P(X,Y) lorsqu'on connait déjà P(X)et P(Y).